|
|
Online Data Quality Monitoring |
|
|
Online Data Quality Monitoring |
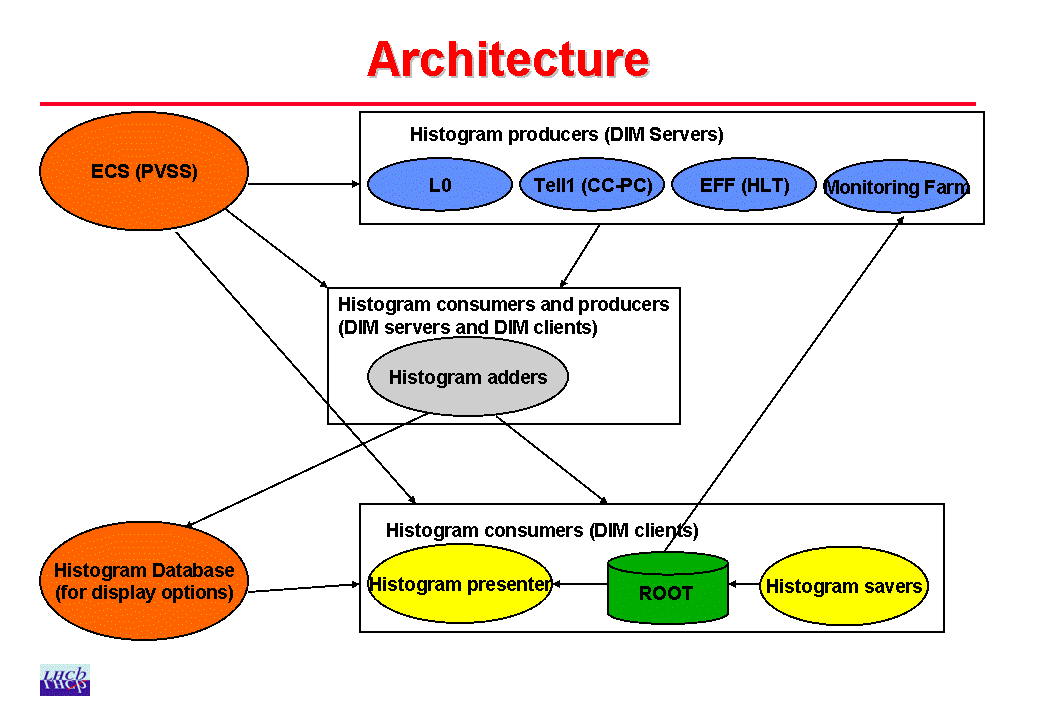
The quality of the data produced by an experiment depends on the proper functioning of the apparatus throughout the data taking period. It is desirable to detect problems as early as possible, so that they can be fixed without compromising a significant fraction of the data. This is best done by monitoring the data online. In the LHCb online data quality monitoring, a variety of monitoring tasks running at different levels in the readout chain and in the Monitoring Farm (MF) process the data into histograms, which are then displayed online by a histogram presenter and analysed at regular intervals by dedicated analysis tasks. A schematic picture showing the architecture of the data quality framework is available here.
Histograms are usually one-dimensional (1D), or profile histograms, but they can also be 0D, i.e. single counters, or 2D, i.e. scatter plots. They are booked and filled in Gaudi-based processes. The booking and filling is done by the tasks that also execute the monitoring code. Histograms will be part of the MonitorSrv of Gaudi and will be published to the external world via the Distributed Information Manager DIM .
Histograms can be produced by a single task, or by several identical tasks running each on part of the events to be monitored. This will clearly be the case for the Event Filter Farm (EFF), and may also be the case for the MF. Indeed, the interesting quantity is usually the summed histogram, sum of all the individual histograms on all nodes. Therefore histograms will be sent to intermediate adders, before being saved. Histograms can also be produced by programs running on the Credit Card PCs imbedded in the TELL1s. Information on histogramming on CC-PCs can be found here.
Monitoring tasks should use as little resources as possible from the EFF HLT CPUs, whose main purpose is to make the best possible trigger decisions. The only reason to monitor on the EFF is study the HLT rejected events, which are not available later. The bulk of the histograms will be produced in the MF, running on HLT accepted events.
The Histogram Presenter will be one of the main tools to understand the status of the experiment, and to guarantee the best quality of the recorded data. It will allow the visualization of all data quality histograms in online as well as history mode. It will also provide a stable configuration, with well defined display pages, for the shift crew to follow. Information on the prototype being developed can be found here.
A Histogram Data Base (HDB) is used to keep track and handle in a consistent and standardized way the large number of histograms produced to monitor the data. An HDB User's manual is available here.
The HDB will store the histogram definitions, rather than the histograms themselves, which will be published and stored as ROOT files. It will contain all the variables needed by the operations of histogram resetting, saving, displaying and analyzing. There will be no duplication of information, so that any information that can be found from the DIM service name or the DIM buffer will not be stored in the database. The HDB will also contain definitions on how the histograms are logically grouped. Groupings of histograms are made for a number of reasons:
to find the set of histograms belonging to a particular task;
to find the set of histograms to be displayed together on the same Page by the histogram presenter;
to find the "Saveset" of histograms to be saved, reset or analysed at the same time.
Each histogram will in fact be associated to a saveset, which determines the periodicity of saving of histograms belonging to the set. All histograms of a set should correspond to the same statistics, i.e. all histograms correspond to the same number of events analyzed.
To facilitate the insertion of histogram data in the HDB, a process running on the level of the highest level Adder (all histograms displayed by the presenter will in fact go through it) will browse though the available DIM histogram services and add them to the HDB.
Histograms will be saved as ROOT files at regular intervals (“monitoring cycles”); in any case at end of run/fill and/or at specified intervals, which are generally different for different savesets. When a set of histograms is saved to disk, the analysis task associated to this saveset will analyse the shapes of the histograms, producing alarms if anomalies are found . Histograms will be reset at the beginning of each run (current thinking is not to reset at the source, but rather to save differentials according to the saveset properties).
The analysis tasks will be sub-detector specific. However an analysis library will provide standard software tools to analyse the histograms, such a simple calculations of means, channels by channels comparisons with expectations using reference files, spike detections fitting the histogram profiles, etc. Any anomalies are tested against a database of known problems and a message sent to the controls system if the problem is new.
Meeting between Root team and LHCb online, 12 june 2007 (agenda, slides ppt, pdf)
Meeting between Root team and LHCb online, 28 september 2007 (slides pdf, minutes word, minutes pdf)
| First thoughts on OnlineMonitoring | EDMS 698614 | released | 24/02/2006 |
| Histogramming Framework | EDMS 748834 | released | 15/06/2006 |
| Histogram DB and Analysis Tools for Online Monitoring | EDMS 774740 | released | 19/9/2006 |
This Twiki page contains useful instructions on how to publish histograms in the Online context and how to use the presenter to view them.
| This page last edited by MPA on October 05, 2007. |
{kind=link}